Word tokenization and embedding
Preparing text for large language model training
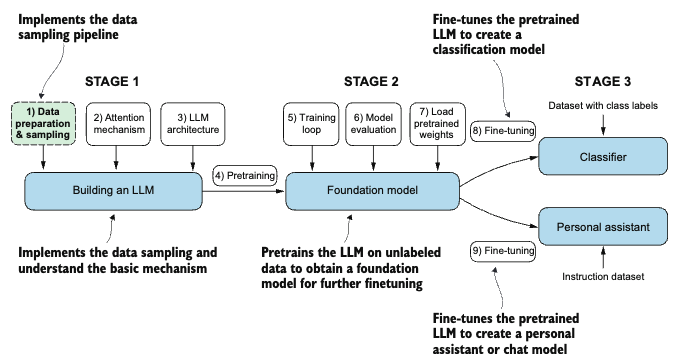
Understanding word embeddings
Since text are unstructured and categorical type of data, deep neural networks in general cannot process (do mathematical operations) on them directly. This motivates us to find a numeric representation for textual data. Such concept of converting from textual data to numeric representation is often referred to as embedding.
NoteEmbedding
Converting from textual data to numeric representation.
Akin to textual data, other types of unstructured data like images and audio also requires this conversion step for deep neural network to process them. Each type of data requires a different type of embedding model.
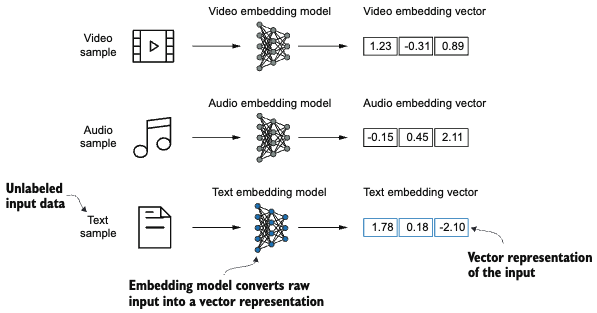
Intuitively, an embedding is a mapping from discrete objects (like images, words) to points in a continuous vector space. Other than word embeddings, there are also other types of embedding such as sentence embedding or paragraph embeddings for different applications.
Word2Vec
“You shall know a word by the companies it keeps.”
There are numerous approaches that have been proposed for word embedding, including TF-IDF. One of the earliest frameworks for word embedding is Word2Vec. As the name implies, the Word2Vec approach aims to convert words to vectors by training a neural network architecture to predict the context of a word given the target word and vice versa.
Imagine the sentence:
The cat sits on the mat.
Step 1: Define context window
Using a window size of 2, the context of the target word is its 2 neighboring words on each side.
- For “cat” (target word): Context =
["The", "sits"] - For “sits” (target word): Context =
["cat", "on"]
Step 2: Training Objective
Word2Vec optimizes one of two objectives:
- CBOW (Continuous Bag of Words): Predict the target word (“cat”) from its context words [“The”, “sits”].
- Skip-gram: Predict the context words [“The”, “sits”] from the target word (“cat”).
Step 3: Output After training, each word (e.g., “cat”) is represented as a dense vector (e.g., [0.2, 0.8, -0.5, ...]) in a continuous vector space where similar words (like “cat” and “dog”) have closer vectors.
The dimension of word embeddings can vary significantly, from one to thousands of dimensions. The higher the dimension, the more relationships between words the embedding can capture, but this comes at a computational cost. The embedding size of GPT-2 and GPT-3, for example, is respectively 768 and 12.288 dimensions.
In the context of LLM development, it is often the case that we train a seperate embedding layer (that is a part of the input layer) instead of ultilizing some pre-trained embedding model like Word2Vec.
Text tokenization
Splitting text into word tokens
Prior to creating embeddings, it is essential to split the sequence into seperate tokens. These tokens can either be a word, a special character, or a subword.
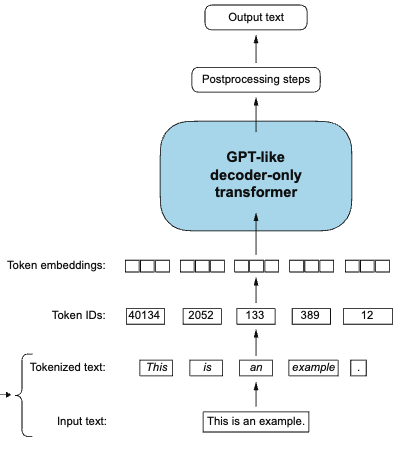
Note
Download the-verdict.txt file here.
with open("the-verdict.txt", "r", encoding="utf-8") as f:
raw_text = f.read()
print("Total number of character: ", len(raw_text))
print(raw_text[:50])Total number of character: 20479
I HAD always thought Jack Gisburn rather a cheap gThere are multiple ways to split this 20479-character text into individual words. The simplest way is to use regular expressionn (regex) syntax. The code snippet below gives a simple example that use the re library to split the text sequence based on whitespace (\s).
import re
text = "Hello, world. This is a test."
result = re.split(r'(\s)', text)
print(result)['Hello,', ' ', 'world.', ' ', 'This', ' ', 'is', ' ', 'a', ' ', 'test.']One problem quickly arises where some words are still attached to the punctuation (eg Hello,). Therefore, we additionally split the text based on the commas and periods:
result = re.split(r'([,.]|\s)', text)
print(result)['Hello', ',', '', ' ', 'world', '.', '', ' ', 'This', ' ', 'is', ' ', 'a', ' ', 'test', '.', '']A small remaining problem is that the list still includes whitespace characters. Optionally, we can remove these redundant characters safely as follows:
result = [item for item in result if item.strip()]
print(result)['Hello', ',', 'world', '.', 'This', 'is', 'a', 'test', '.']Let’s try for a more complicated text sequence to see if our tokenization scheme works well. Here, we add some more punctuations.
text = "Hello, world. Is this-- a test?"
result = re.split(r'([,.:;?_!"()\']|--|\s)', text)
result = [item.strip() for item in result if item.strip()]
print(result)['Hello', ',', 'world', '.', 'Is', 'this', '--', 'a', 'test', '?']Now we’re ready to apply this basic tokenizer to the raw_text that contain our scopus, which is the-verdict.txt:
preprocessed = re.split(r'([,.:;?_!"()\']|--|\s)', raw_text)
preprocessed = [item.strip() for item in preprocessed if item.strip()]
print(preprocessed[:10])
print(len(preprocessed))['I', 'HAD', 'always', 'thought', 'Jack', 'Gisburn', 'rather', 'a', 'cheap', 'genius']
4690Converting text into token IDs
Our next step is to convert these tokens into an integer representation to produce the token IDs. This is an intermediate step from converting raw text (words) into embeddings.
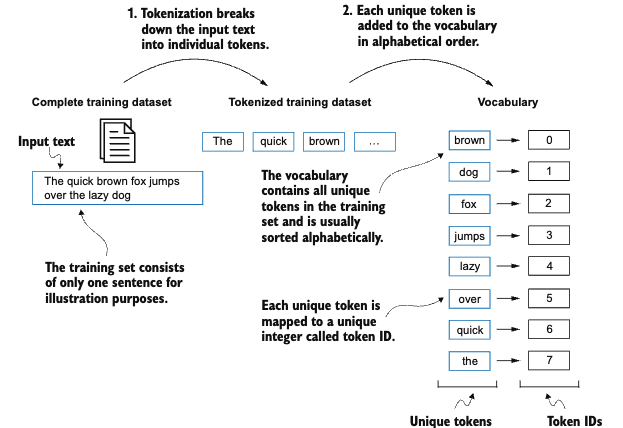
all_words = sorted(set(preprocessed))
vocab_size = len(all_words)
print(vocab_size)1130We can now create a vocabulary, which is roughly a dictionary that contains individual tokens associated with unique integer labels.
vocab = {token:integer for integer, token in enumerate(all_words)}
for i, item in enumerate(vocab.items()):
print(item)
if i>=20:
break('!', 0)
('"', 1)
("'", 2)
('(', 3)
(')', 4)
(',', 5)
('--', 6)
('.', 7)
(':', 8)
(';', 9)
('?', 10)
('A', 11)
('Ah', 12)
('Among', 13)
('And', 14)
('Are', 15)
('Arrt', 16)
('As', 17)
('At', 18)
('Be', 19)
('Begin', 20)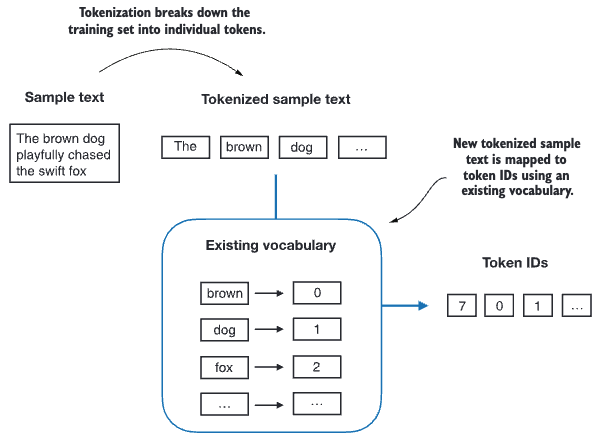
Of course we would also like to convert from the token IDs back to the actual word. This can simply be implemented by reversing what we’ve done in the previous step. By now, we’re ready to create a tokenizer class that combine everything together:
class SimpleTokenizerv1:
def __init__(self, vocab):
1 self.str_to_int = vocab
2 self.int_to_str = {i:s for s,i in vocab.items()}
def encode(self, text):
'''
encode input text into token IDs
'''
preprocessed = re.split(r'([,.?_!"()\']|--|\s)', text)
preprocessed = [item.strip() for item in preprocessed if item.strip()]
ids = [self.str_to_int[s] for s in preprocessed]
return ids
def decode(self, ids):
text = " ".join([self.int_to_str[i] for i in ids])
text = re.sub(r'\s+([,.?])', r'\1', text)
return text - 1
- Stores the vocabulary as a class attribute for access in the encode and decode methods.
- 2
- Create an inverse mapping from token IDs to text tokens.
Now we can tokenize our corpus:
tokenizer = SimpleTokenizerv1(vocab)
text = """"It's the last he painted, you know," Mrs. Gisburn said with pardonable pride."""
ids = tokenizer.encode(text)
print(ids)[1, 56, 2, 850, 988, 602, 533, 746, 5, 1126, 596, 5, 1, 67, 7, 38, 851, 1108, 754, 793, 7]Let’s see if our tokenizer can actually convert these IDs back into the input sequence:
print(tokenizer.decode(ids))" It ' s the last he painted, you know, " Mrs. Gisburn said with pardonable pride.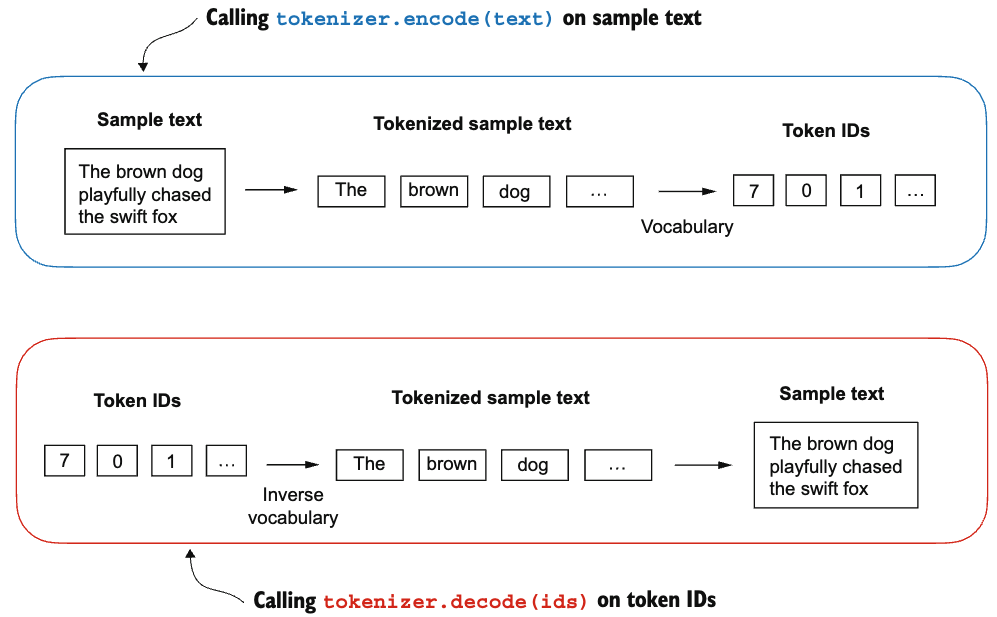
Adding special text tokens
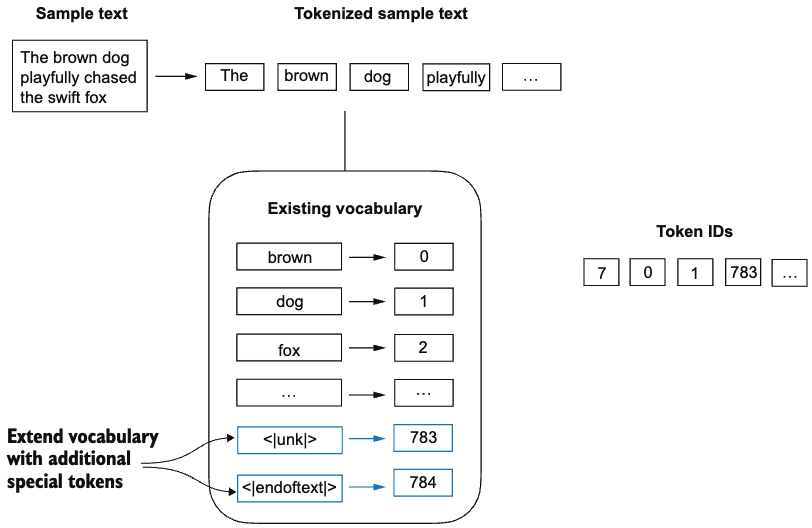
We can modify the tokenizer to use an <|unk|> token if it encounters a word that is not part of the vocabulary. Furthermore, we add a token between unrelated texts.
all_tokens = sorted(list(set(preprocessed)))
all_tokens.extend(['<|endoftext|>', '<|unk|>'])
vocab = {token:integer for integer, token in enumerate(all_tokens)}
print(len(vocab.items()))1132Let’s now do a quick sanity check if we’ve successfully incorporated the new special tokens in to the vocab:
for i, item in enumerate(list(vocab.items())[-5:]):
print(item)('younger', 1127)
('your', 1128)
('yourself', 1129)
('<|endoftext|>', 1130)
('<|unk|>', 1131)Let’s wrap everything up into a compact class:
class SimpleTokenizerv2:
def __init__(self, vocab):
self.str_to_int = vocab
self.int_to_str = {i:s for s,i in vocab.items()}
def encode(self, text):
preprocessed = re.split(r'([,.:;?_!"()\']|--|\s)', text)
preprocessed = [item.strip() for item in preprocessed if item.strip()]
preprocessed = [item if item in self.str_to_int else "<|unk|>" for item in preprocessed]
ids = [self.str_to_int[s] for s in preprocessed]
return ids
def decode(self, ids):
text = " ".join([self.int_to_str[i] for i in ids])
text = re.sub(r'\s+([,.:;?!"()\'])', r'\1', text)
return texttext1 = "Hello, do you like tea ?"
text2 = "In the sunlit terraces of the palace"
text = "<|endoftext|>".join((text1, text2))
print(text)
tokenizer = SimpleTokenizerv2(vocab)
print(tokenizer.encode(text))
print(tokenizer.decode(tokenizer.encode(text)))Hello, do you like tea ?<|endoftext|>In the sunlit terraces of the palace
[1131, 5, 355, 1126, 628, 975, 10, 1131, 988, 956, 984, 722, 988, 1131]
<|unk|>, do you like tea? <|unk|> the sunlit terraces of the <|unk|>Byte pair encoding as a more advanced way of tokenizing text
Check the tiktoken library version:
from importlib.metadata import version
import tiktoken
print("Tiktoken version: ", version("tiktoken"))Tiktoken version: 0.12.0We can then instantiate the BPE tokenizer:
tokenizer = tiktoken.get_encoding("gpt2")text = "Hello, do you like tea ? <|endoftext|> In the sunlit terraces of someunknownPlace."
integers = tokenizer.encode(text, allowed_special={"<|endoftext|>"})
print(integers)[15496, 11, 466, 345, 588, 8887, 5633, 220, 50256, 554, 262, 4252, 18250, 8812, 2114, 286, 617, 34680, 27271, 13]strings = tokenizer.decode(integers)
print(strings)Hello, do you like tea ? <|endoftext|> In the sunlit terraces of someunknownPlace.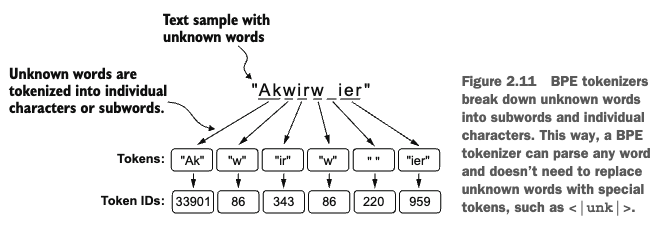
Sampling training examples with a sliding window approach
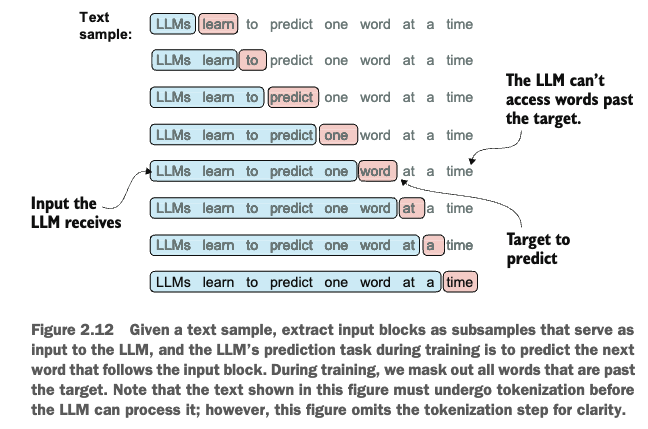
with open("the-verdict.txt", "r", encoding = "utf-8") as f:
raw_text = f.read()
enc_text = tokenizer.encode(raw_text)
enc_sample = enc_text[50:]
print(len(enc_text))5145context_size = 4
x = enc_sample[:context_size]
y = enc_sample[1:context_size+1]
print(f"x: {x}")
print(f"y: {y}")x: [290, 4920, 2241, 287]
y: [4920, 2241, 287, 257]for i in range(1, context_size+1):
context = enc_sample[:i]
target = enc_sample[i]
print(context, "----->", target)[290] -----> 4920
[290, 4920] -----> 2241
[290, 4920, 2241] -----> 287
[290, 4920, 2241, 287] -----> 257
import torch
from torch.utils.data import Dataset, DataLoader
class GPTDatasetV1(Dataset):
def __init__(self, txt, tokenizer, max_length, stride):
self.input_ids = []
self.target_ids = []
1 token_ids = tokenizer.encode(txt)
2 for i in range(0, len(token_ids) - max_length, stride):
input_chunk = token_ids[i:i+max_length]
target_chunk = token_ids[i+1:i+max_length+1]
self.input_ids.append(torch.tensor(input_chunk))
self.target_ids.append(torch.tensor(target_chunk))
def __len__(self):
return len(self.input_ids)
def __getitem__(self, idx):
3 return self.input_ids[idx], self.target_ids[idx]- 1
- Tokenize the entire text
- 2
-
Use sliding window to chunk the text into overlapping sequences of
max_length - 3
- Returns a single row from the dataset.
Next we can load the inputs in batches via PyTorch’s DataLoader
def create_dataloader_v1(txt,
batch_size=4,
max_length=256,
stride=128,
shuffle=True,
drop_last=True,
num_workers=0):
tokenizer = tiktoken.get_encoding('gpt2')
dataset = GPTDatasetV1(txt, tokenizer, max_length, stride)
dataloader = DataLoader(
dataset,
batch_size = batch_size,
shuffle = shuffle,
drop_last = drop_last,
num_workers = num_workers
)
return dataloaderwith open("the-verdict.txt", "r", encoding="utf-8") as f:
raw_text = f.read()
dataloader = create_dataloader_v1(raw_text,
batch_size=1,
max_length=4,
stride = 1,
shuffle=False)
data_iter = iter(dataloader)
first_batch = next(data_iter)
print(first_batch)[tensor([[ 40, 367, 2885, 1464]]), tensor([[ 367, 2885, 1464, 1807]])]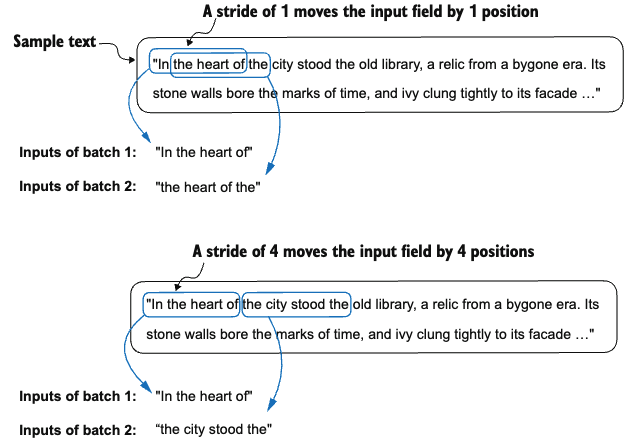
dataloader = create_dataloader_v1(raw_text,
batch_size=8,
max_length=4,
stride=4,
shuffle=False)
data_iter = iter(dataloader)
inputs, targets = next(data_iter)
print("Inputs: \n", inputs)
print("\n Targets: \n", targets)Inputs:
tensor([[ 40, 367, 2885, 1464],
[ 1807, 3619, 402, 271],
[10899, 2138, 257, 7026],
[15632, 438, 2016, 257],
[ 922, 5891, 1576, 438],
[ 568, 340, 373, 645],
[ 1049, 5975, 284, 502],
[ 284, 3285, 326, 11]])
Targets:
tensor([[ 367, 2885, 1464, 1807],
[ 3619, 402, 271, 10899],
[ 2138, 257, 7026, 15632],
[ 438, 2016, 257, 922],
[ 5891, 1576, 438, 568],
[ 340, 373, 645, 1049],
[ 5975, 284, 502, 284],
[ 3285, 326, 11, 287]])Converting tokens into vectors that feed into a large language model
Creating token embedding
The last step in preparing the input text for LLM training is to convert the token IDs into embedding vectors.
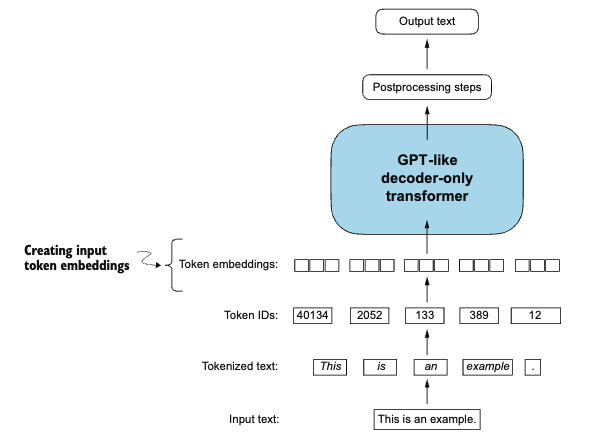
Suppose we have a vocabulary containing only 6 words, and we want to create an embedding of size 3 (an embedding that has 3 dimensions).
input_ids = torch.tensor([2,3,5,1])
vocab_size = 6
output_dim = 3
torch.manual_seed(123)
embedding_layer = torch.nn.Embedding(vocab_size, output_dim)
print(embedding_layer.weight)Parameter containing:
tensor([[ 0.3374, -0.1778, -0.1690],
[ 0.9178, 1.5810, 1.3010],
[ 1.2753, -0.2010, -0.1606],
[-0.4015, 0.9666, -1.1481],
[-1.1589, 0.3255, -0.6315],
[-2.8400, -0.7849, -1.4096]], requires_grad=True)print(embedding_layer(torch.tensor([3])))tensor([[-0.4015, 0.9666, -1.1481]], grad_fn=<EmbeddingBackward0>)print(embedding_layer(input_ids))tensor([[ 1.2753, -0.2010, -0.1606],
[-0.4015, 0.9666, -1.1481],
[-2.8400, -0.7849, -1.4096],
[ 0.9178, 1.5810, 1.3010]], grad_fn=<EmbeddingBackward0>)Encoding word positions
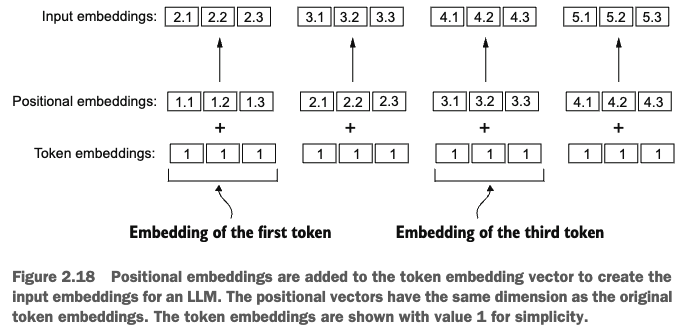
vocab_size = 50257
output_dim = 256
token_embedding_layer = torch.nn.Embedding(vocab_size, output_dim)max_length = 4
dataloader = create_dataloader_v1(
raw_text, batch_size = 8, max_length=max_length,
stride = max_length, shuffle = False
)
data_iter = iter(dataloader)
inputs, targets = next(data_iter)
print("Token IDs: \n", inputs)
print("\n Input shape: \n", inputs.shape)Token IDs:
tensor([[ 40, 367, 2885, 1464],
[ 1807, 3619, 402, 271],
[10899, 2138, 257, 7026],
[15632, 438, 2016, 257],
[ 922, 5891, 1576, 438],
[ 568, 340, 373, 645],
[ 1049, 5975, 284, 502],
[ 284, 3285, 326, 11]])
Input shape:
torch.Size([8, 4])token_embeddings = token_embedding_layer(inputs)
print(token_embeddings.shape)torch.Size([8, 4, 256])context_length = max_length
pos_embedding_layer = torch.nn.Embedding(context_length, output_dim)
1pos_embeddings = pos_embedding_layer(torch.arange(context_length))
print(pos_embeddings.shape)- 1
-
The input to the
pos_embeddingsis usually a placeholder vectortorch.arange(context_length), which contains a sequence of numbers 0, 1, …, up to the maximum input length –1.
torch.Size([4, 256])input_embedding = token_embeddings + pos_embeddings
print(input_embedding.shape)torch.Size([8, 4, 256])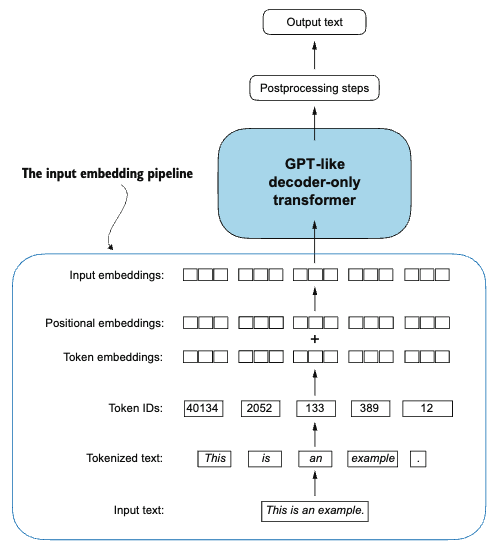
Quiz
From Question 1-5, find an error in the code snippets and correct them.
Question 1.
class SimpleTokenizerv1:
def __init__(self, vocab):
self.str_to_int = vocab
self.int_to_str = {i:s for s,i in vocab.items()}
def encode(self, text):
'''
encode input text into token IDs
'''
preprocessed = re.split(r'([,.?_!"()\']|--|\s)', text)
preprocessed = [item.strip() for item in preprocessed if item.strip()]
ids = [self.str_to_int[s] for s in preprocessed]
return ids
def decode(self, ids):
text = " ".join([self.str_to_int[i] for i in ids])
text = re.sub(r'\s+([,.?])', r'\1', text)
return text Question 2.
all_tokens = sorted(list(set(preprocessed)))
all_tokens.extend('<|endoftext|>', '<|unk|>')
vocab = {token:integer for integer, token in enumerate(all_tokens)}
print(len(vocab.items()))Question 3.
class SimpleTokenizerv2:
def __init__(self, vocab):
self.str_to_int = vocab
self.int_to_str = {i:s for s, in vocab.items()}
def encode(self, text):
preprocessed = re.split(r'([,.:;?_!"()\']|--|\s)', text)
preprocessed = [item.strip() for item in preprocessed if item.strip()]
preprocessed = [item for item in self.str_to_int else "<unk>" for item in preprocessed]
ids = [self.str_to_int[s] for s in preprocessed]
return ids
def decode(self, ids):
text = " ".join([self.str_to_int[i] for i in ids])
text = re.sub(r'([,.:;?_!"()\']|--|\s)', text)
return textFurther Resources
- Word2Vec paper: Efficient Estimation of Word Representations in Vector Space