import torch
inputs = torch.tensor(
[[0.43, 0.15, 0.89], # Your (x^1)
[0.55, 0.87, 0.66], # journey (x^2)
[0.57, 0.85, 0.64], # starts (x^3)
[0.22, 0.58, 0.33], # with (x^4)
[0.77, 0.25, 0.10], # one (x^5)
[0.05, 0.80, 0.55]] # step (x^6)
)Attention mechanism
llm
attention
Note
- Compute the attention scores.
- Normalize the attention scores to obtain the attention weights.
- Calculate the context vector.
A primer of Attention mechanism
Computing the context vectors
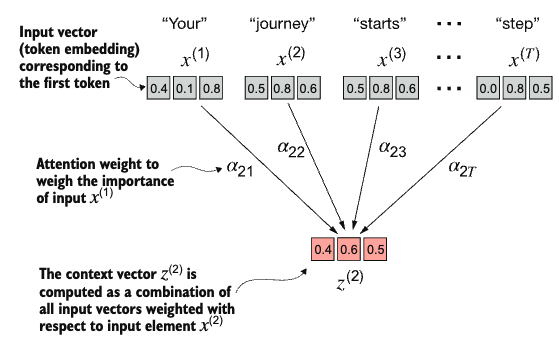
Note
The goal of self-attention is to compute a context vector for each input elements that combines the information from all other input elements.
Consider an input text like Your journey starts with one step. Each element of the sequence \(x^{(i)}\) corresponds to a \(d\)-dimensional embedding vector representing a specific token. In self-attention, the goal is to calculate the context vector \(z^{(i)}\) for each element \(x^{(i)}\) in the input sequence. A context vector can be interpreted as an enriched embedding vector. Context vector plays a crucial role in self-attention. Their purpose is to create enriched representations of each element in an input sequence by incorporating information from all other elements in the sequence.
Attention scores
The first step in implementing self-attention is to compute the attention scores \(\omega\), as shown in the figure below. The attention scores are computed by taking the dot product of the query and the key vectors.
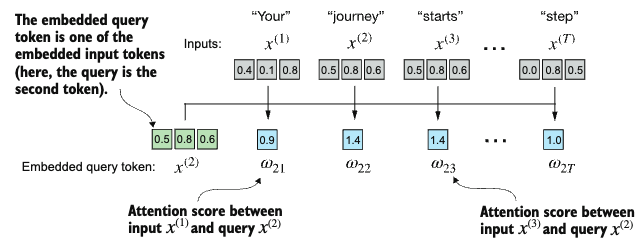
For example, the attention score given the query \(x^{(2)}\) is computed as follows:
query = inputs[1]
attn_scores_2 = torch.empty(inputs.shape[0])
for i, x_i in enumerate(inputs):
attn_scores_2[i] = torch.dot(x_i, query)
print(attn_scores_2)tensor([0.9544, 1.4950, 1.4754, 0.8434, 0.7070, 1.0865])Next, we normalize the attention scores to obtain the attention weights that sum up to 1. One simple way to do this is to divide the attention scores by the sum of the attention scores.
attn_weights_2 = attn_scores_2 / attn_scores_2.sum()
print(attn_weights_2)
print(attn_weights_2.sum())tensor([0.1455, 0.2278, 0.2249, 0.1285, 0.1077, 0.1656])
tensor(1.0000)In practice, it’s more common to use the Softmax function for normalization, which makes the output interpretable as a probability distribution.
attn_weights_2 = torch.softmax(attn_scores_2, dim=0)
print(attn_weights_2)
print(attn_weights_2.sum())tensor([0.1385, 0.2379, 0.2333, 0.1240, 0.1082, 0.1581])
tensor(1.)Now we can compute the context vector for the query \(x^{(2)}\) by multiplying the attention weights by the input vectors and summing the resulting vectors.
query = inputs[1]
context_vec_2 = torch.zeros(query.shape)
for i, x_i in enumerate(inputs):
context_vec_2 += attn_weights_2[i]*x_i
print(context_vec_2)tensor([0.4419, 0.6515, 0.5683])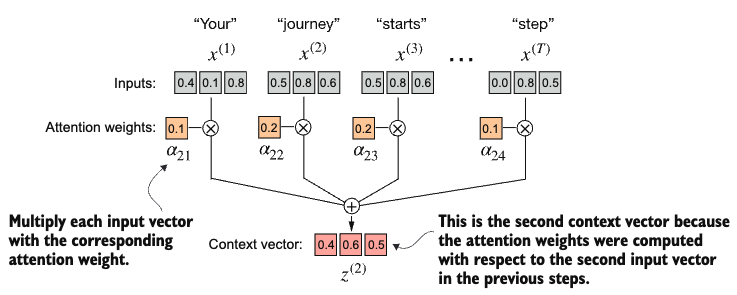
Computing attention weights for all input tokens
We can now generalize to compute the context vectors for all of the tokens in the input sequence.
attn_scores = torch.empty(6,6)
for i, x_i in enumerate(inputs):
for j, x_j in enumerate(inputs):
attn_scores[i, j] = torch.dot(x_i, x_j)
print(attn_scores)tensor([[0.9995, 0.9544, 0.9422, 0.4753, 0.4576, 0.6310],
[0.9544, 1.4950, 1.4754, 0.8434, 0.7070, 1.0865],
[0.9422, 1.4754, 1.4570, 0.8296, 0.7154, 1.0605],
[0.4753, 0.8434, 0.8296, 0.4937, 0.3474, 0.6565],
[0.4576, 0.7070, 0.7154, 0.3474, 0.6654, 0.2935],
[0.6310, 1.0865, 1.0605, 0.6565, 0.2935, 0.9450]])However, nested for loops are bad, we can use matrix multiplication to achieve the same result:
attn_scores = inputs @ inputs.T
print(attn_scores)tensor([[0.9995, 0.9544, 0.9422, 0.4753, 0.4576, 0.6310],
[0.9544, 1.4950, 1.4754, 0.8434, 0.7070, 1.0865],
[0.9422, 1.4754, 1.4570, 0.8296, 0.7154, 1.0605],
[0.4753, 0.8434, 0.8296, 0.4937, 0.3474, 0.6565],
[0.4576, 0.7070, 0.7154, 0.3474, 0.6654, 0.2935],
[0.6310, 1.0865, 1.0605, 0.6565, 0.2935, 0.9450]])Now we can normalize the attention scores to obtain the attention weights:
1attn_weights = torch.softmax(attn_scores, dim=-1)
print(attn_weights)- 1
-
In the context of using PyTorch, the dim parameter in functions like
torch.softmaxspecifies the dimension of the input tensor along which the function will be com- puted. By setting dim=-1, we are instructing the softmax function to apply the nor- malization along the last dimension of the attn_scores tensor. Ifattn_scoresis a two-dimensional tensor (for example, with a shape of[rows, columns]), it will nor- malize across the columns so that the values in each row (summing over the column dimension) sum up to 1.
tensor([[0.2098, 0.2006, 0.1981, 0.1242, 0.1220, 0.1452],
[0.1385, 0.2379, 0.2333, 0.1240, 0.1082, 0.1581],
[0.1390, 0.2369, 0.2326, 0.1242, 0.1108, 0.1565],
[0.1435, 0.2074, 0.2046, 0.1462, 0.1263, 0.1720],
[0.1526, 0.1958, 0.1975, 0.1367, 0.1879, 0.1295],
[0.1385, 0.2184, 0.2128, 0.1420, 0.0988, 0.1896]])Now we can compute the context vectors for all of the tokens in the input sequence:
all_context_vecs = attn_weights @ inputs
print(all_context_vecs)
print("Previous context vector:", context_vec_2)tensor([[0.4421, 0.5931, 0.5790],
[0.4419, 0.6515, 0.5683],
[0.4431, 0.6496, 0.5671],
[0.4304, 0.6298, 0.5510],
[0.4671, 0.5910, 0.5266],
[0.4177, 0.6503, 0.5645]])
Previous context vector: tensor([0.4419, 0.6515, 0.5683])Implementing self-attention with trainable weights
We can now implement self-attention mechanism used in the original Transformer model. This self-attention mechanism is also known as scaled dot-product attention.
First, let \(\mathbf{W}_q\), \(\mathbf{W}_k\), and \(\mathbf{W}_v\) be the weight matrices for the query, key, and value vectors, respectively. The query, key, and value vectors are computed as follows:
x_2 = inputs[1] # the second input element
d_in = inputs.shape[1] # the input embedding size d_in
d_out = 2 # the output embedding size d_outNow initialize the weight matrices:
torch.manual_seed(123)
1W_query = torch.nn.Parameter(torch.randn(d_in, d_out), requires_grad=True)
W_key = torch.nn.Parameter(torch.randn(d_in, d_out), requires_grad=True)
W_value = torch.nn.Parameter(torch.randn(d_in, d_out), requires_grad=True)- 1
-
The
requires_grad=Trueflag indicates that the weight matrices are trainable, meaning that their values can be updated during training.
Now we can compute the query, key, and value vectors:
query_2 = x_2 @ W_query
key_2 = x_2 @ W_key
value_2 = x_2 @ W_value
print(query_2)tensor([-1.1729, -0.0048], grad_fn=<SqueezeBackward4>)We can obtain all keys and value vectors via matrix multiplication:
keys = inputs @ W_key
values = inputs @ W_value
print("keys.shape:", keys.shape)
print("values.shape:", values.shape)keys.shape: torch.Size([6, 2])
values.shape: torch.Size([6, 2])Next we compute the attention scores. For illustration, we first compute the attention score \(\omega_{22}\):
keys_2 = keys[2]
attn_score_22 = torch.dot(query_2, keys_2)
print(attn_score_22)tensor(0.1730, grad_fn=<DotBackward0>)Now we can generlize this and compute the attention scores for all the tokens:
attn_scores_2 = query_2 @ keys.T # all attention scores for given query
print(attn_scores_2)tensor([ 0.2172, 0.1376, 0.1730, -0.0491, 0.7616, -0.3809],
grad_fn=<SqueezeBackward4>)Now compute the attention weights:
d_k = keys.shape[-1]
attn_weights_2 = torch.softmax(attn_scores_2 / d_k**0.5, dim=-1)
print(attn_weights_2)tensor([0.1704, 0.1611, 0.1652, 0.1412, 0.2505, 0.1117],
grad_fn=<SoftmaxBackward0>)Now we can compute the context vector for the query \(x^{(2)}\) by multiplying the attention weights by the value vectors and summing the resulting vectors:
context_vec_2 = attn_weights_2 @ values
print(context_vec_2)tensor([0.2854, 0.4081], grad_fn=<SqueezeBackward4>)We can now generalize this to compute the context vectors for all the tokens:
all_context_vecs = attn_weights @ values
print(all_context_vecs)tensor([[0.2908, 0.3580],
[0.3117, 0.4242],
[0.3114, 0.4243],
[0.3021, 0.4108],
[0.2979, 0.4191],
[0.3058, 0.4103]], grad_fn=<MmBackward0>)A compact self-attention Python class
import torch.nn as nn
class SelfAttention_v1(nn.Module):
def __init__(self, d_in, d_out):
super().__init__()
self.W_query = nn.Parameter(torch.randn(d_in, d_out), requires_grad=True)
self.W_key = nn.Parameter(torch.randn(d_in, d_out), requires_grad=True)
self.W_value = nn.Parameter(torch.randn(d_in, d_out), requires_grad=True)
def forward(self, x):
queries = x @ self.W_query
keys = x @ self.W_key
values = x @ self.W_value
attn_scores = queries @ keys.T
attn_weights = torch.softmax(attn_scores / d_k**0.5, dim=-1)
context_vecs = attn_weights @ values
return context_vecsWe can use this class as follows:
torch.manual_seed(123)
sa_v1 = SelfAttention_v1(d_in=3, d_out=2)
print(sa_v1(inputs))tensor([[0.2845, 0.4071],
[0.2854, 0.4081],
[0.2854, 0.4075],
[0.2864, 0.3974],
[0.2863, 0.3910],
[0.2860, 0.4039]], grad_fn=<MmBackward0>)Instead of nn.Parameter, we can use nn.Linear to initialize the weight matrices:
import torch.nn as nn
class SelfAttention_v2(nn.Module):
def __init__(self, d_in, d_out):
super().__init__()
self.W_query = nn.Linear(d_in, d_out)
self.W_key = nn.Linear(d_in, d_out)
self.W_value = nn.Linear(d_in, d_out)
def forward(self, x):
queries = self.W_query(x)
keys = self.W_key(x)
values = self.W_value(x)
attn_scores = queries @ keys.T
attn_weights = torch.softmax(attn_scores / d_k**0.5, dim=-1)
context_vecs = attn_weights @ values
return context_vecsWe can use this class as follows:
torch.manual_seed(123)
sa_v2 = SelfAttention_v2(d_in=3, d_out=2)
print(sa_v2(inputs))tensor([[0.1059, 0.9296],
[0.1144, 0.9353],
[0.1143, 0.9353],
[0.1181, 0.9369],
[0.1138, 0.9343],
[0.1188, 0.9375]], grad_fn=<MmBackward0>)Hiding future words with causal attention
Many LLM tasks require the model to focus on the current word and the words that precede it in the sequence. This is achieved by using causal attention, which masks out the future words.
Causal attention mask
Previous we compute the attention weights:
queries = sa_v2.W_query(inputs)
keys = sa_v2.W_key(inputs)
values = sa_v2.W_value(inputs)
attn_scores = queries @ keys.T
attn_weights = torch.softmax(attn_scores / d_k**0.5, dim=-1)
print(attn_weights)tensor([[0.1838, 0.1672, 0.1678, 0.1557, 0.1745, 0.1511],
[0.1780, 0.1756, 0.1750, 0.1552, 0.1547, 0.1615],
[0.1780, 0.1754, 0.1749, 0.1553, 0.1550, 0.1614],
[0.1733, 0.1770, 0.1761, 0.1572, 0.1497, 0.1667],
[0.1770, 0.1734, 0.1731, 0.1569, 0.1585, 0.1611],
[0.1731, 0.1780, 0.1769, 0.1568, 0.1478, 0.1674]],
grad_fn=<SoftmaxBackward0>)In PyTorch, we can use the torch.tril function to create a causal attention mask. It basically mask out the upper triangular part of the attention weights:
context_length = attn_scores.shape[0]
mask_simple = torch.tril(torch.ones(context_length, context_length))
print(mask_simple)tensor([[1., 0., 0., 0., 0., 0.],
[1., 1., 0., 0., 0., 0.],
[1., 1., 1., 0., 0., 0.],
[1., 1., 1., 1., 0., 0.],
[1., 1., 1., 1., 1., 0.],
[1., 1., 1., 1., 1., 1.]])masked_simple = attn_weights * mask_simple
print(masked_simple)tensor([[0.1838, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000],
[0.1780, 0.1756, 0.0000, 0.0000, 0.0000, 0.0000],
[0.1780, 0.1754, 0.1749, 0.0000, 0.0000, 0.0000],
[0.1733, 0.1770, 0.1761, 0.1572, 0.0000, 0.0000],
[0.1770, 0.1734, 0.1731, 0.1569, 0.1585, 0.0000],
[0.1731, 0.1780, 0.1769, 0.1568, 0.1478, 0.1674]],
grad_fn=<MulBackward0>)Now we need to re-normalize the masked attention weights:
row_sums = masked_simple.sum(dim=-1, keepdim=True)
masked_simple_norm = masked_simple / row_sums
print(masked_simple_norm)tensor([[1.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000],
[0.5034, 0.4966, 0.0000, 0.0000, 0.0000, 0.0000],
[0.3369, 0.3320, 0.3310, 0.0000, 0.0000, 0.0000],
[0.2535, 0.2589, 0.2576, 0.2300, 0.0000, 0.0000],
[0.2110, 0.2067, 0.2063, 0.1871, 0.1890, 0.0000],
[0.1731, 0.1780, 0.1769, 0.1568, 0.1478, 0.1674]],
grad_fn=<DivBackward0>)Masking additional weights with dropout
torch.manual_seed(123)
dropout = torch.nn.Dropout(0.5)
example = torch.ones(6,6)
print(dropout(example))tensor([[2., 2., 0., 2., 2., 0.],
[0., 0., 0., 2., 0., 2.],
[2., 2., 2., 2., 0., 2.],
[0., 2., 2., 0., 0., 2.],
[0., 2., 0., 2., 0., 2.],
[0., 2., 2., 2., 2., 0.]])print(dropout(attn_weights))tensor([[0.3676, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000],
[0.0000, 0.0000, 0.3500, 0.0000, 0.3095, 0.3229],
[0.0000, 0.3509, 0.3498, 0.3105, 0.3100, 0.3227],
[0.0000, 0.0000, 0.3522, 0.3144, 0.0000, 0.3334],
[0.0000, 0.0000, 0.0000, 0.0000, 0.3170, 0.3222],
[0.3463, 0.3559, 0.0000, 0.3135, 0.2956, 0.3349]],
grad_fn=<MulBackward0>)Implementing a compact causal attention class
batch = torch.stack((inputs, inputs), dim=0)
print("batch.shape:", batch.shape)batch.shape: torch.Size([2, 6, 3])class CausalAttention(nn.Module):
def __init__(self, d_in, d_out, context_length, dropout, qkv_bias=False):
super().__init__()
self.d_out = d_out
self.W_query = nn.Linear(d_in, d_out, bias=qkv_bias)
self.W_key = nn.Linear(d_in, d_out, bias=qkv_bias)
self.W_value = nn.Linear(d_in, d_out, bias=qkv_bias)
self.context_length = context_length
self.dropout = nn.Dropout(dropout)
1 self.register_buffer("mask", torch.triu(torch.ones(context_length, context_length), diagonal=1))
def forward(self, x):
b, num_tokens, d_in = x.shape
queries = self.W_query(x)
keys = self.W_key(x)
values = self.W_value(x)
attn_scores = queries @ keys.transpose(1, 2)
attn_scores.masked_fill_(self.mask.bool()[:num_tokens, :num_tokens], -torch.inf)
attn_weights = torch.softmax(attn_scores / keys.shape[-1]**0.5, dim=-1)
attn_weights = self.dropout(attn_weights)
context_vec = attn_weights @ values
return context_vec- 1
-
The use of
register_bufferin PyTorch is not strictly necessary for all use cases but offers several advantages here. For instance, when we use the CausalAttention class in our LLM, buffers are automati- cally moved to the appropriate device (CPU or GPU) along with our model, which will be relevant when training our LLM.
torch.manual_seed(123)
context_length = batch.shape[1]
ca = CausalAttention(d_in, d_out, context_length, 0.0)
context_vecs = ca(batch)
print("context_vecs.shape:", context_vecs.shape)
print("context_vecs:", context_vecs)context_vecs.shape: torch.Size([2, 6, 2])
context_vecs: tensor([[[-0.4519, 0.2216],
[-0.5874, 0.0058],
[-0.6300, -0.0632],
[-0.5675, -0.0843],
[-0.5526, -0.0981],
[-0.5299, -0.1081]],
[[-0.4519, 0.2216],
[-0.5874, 0.0058],
[-0.6300, -0.0632],
[-0.5675, -0.0843],
[-0.5526, -0.0981],
[-0.5299, -0.1081]]], grad_fn=<UnsafeViewBackward0>)Extending single-head attention to multi-head attention
The term ‘multi-head’ refers to dividing the attention mechanism into multiple heads, each operating independently. In practical terms, implementing a multi-head attention involves creating multiple instances of the self-attention mechanism.
class MultiHeadAttentionWrapper(nn.Module):
def __init__(self, d_in, d_out, context_length, dropout, num_heads, qkv_bias=False):
super().__init__()
self.heads = nn.ModuleList(
[CausalAttention(d_in, d_out, context_length, dropout, qkv_bias)
for _ in range(num_heads)]
)
def forward(self, x):
return torch.cat([head(x) for head in self.heads], dim=-1)torch.manual_seed(123)
context_length = batch.shape[1] # number of tokens
d_in, d_out = 3, 2
mha = MultiHeadAttentionWrapper(d_in, d_out, context_length, 0.0, num_heads=2)
context_vecs = mha(batch)
print(context_vecs)
print("context_vecs.shape:", context_vecs.shape)tensor([[[-0.4519, 0.2216, 0.4772, 0.1063],
[-0.5874, 0.0058, 0.5891, 0.3257],
[-0.6300, -0.0632, 0.6202, 0.3860],
[-0.5675, -0.0843, 0.5478, 0.3589],
[-0.5526, -0.0981, 0.5321, 0.3428],
[-0.5299, -0.1081, 0.5077, 0.3493]],
[[-0.4519, 0.2216, 0.4772, 0.1063],
[-0.5874, 0.0058, 0.5891, 0.3257],
[-0.6300, -0.0632, 0.6202, 0.3860],
[-0.5675, -0.0843, 0.5478, 0.3589],
[-0.5526, -0.0981, 0.5321, 0.3428],
[-0.5299, -0.1081, 0.5077, 0.3493]]], grad_fn=<CatBackward0>)
context_vecs.shape: torch.Size([2, 6, 4])Implementing multi-head attention with weight splits
class MultiHeadAttention(nn.Module):
def __init__(self, d_in, d_out, context_length, dropout, num_heads, qkv_bias=False):
super().__init__()
assert (d_out % num_heads == 0), "d_out must be divisible by num_heads"
self.d_out = d_out
self.num_heads = num_heads
# reduces the projection dim to match the desired output dim
self.head_dim = d_out // num_heads
self.W_query = nn.Linear(d_in, d_out, bias=qkv_bias)
self.W_key = nn.Linear(d_in, d_out, bias=qkv_bias)
self.W_value = nn.Linear(d_in, d_out, bias=qkv_bias)
# uses a linear layer to combine head outputs
self.out_proj = nn.Linear(d_out, d_out)
self.dropout = nn.Dropout(dropout)
self.register_buffer("mask", torch.triu(torch.ones(context_length, context_length), diagonal=1))
def forward(self, x):
b, num_tokens, d_in = x.shape
keys = self.W_key(x)
values = self.W_value(x)
queries = self.W_query(x)
keys = keys.view(b, num_tokens, self.num_heads, self.head_dim)
values = values.view(b, num_tokens, self.num_heads, self.head_dim)
queries = queries.view(b, num_tokens, self.num_heads, self.head_dim)
keys = keys.transpose(1,2)
queries = queries.transpose(1,2)
values = values.transpose(1,2)
attn_scores = queries @ keys.transpose(2,3)
mask_bool = self.mask.bool()[:num_tokens, :num_tokens]
attn_scores.masked_fill_(mask_bool, -torch.inf)
attn_weights = torch.softmax(attn_scores / keys.shape[-1]**0.5, dim=-1)
attn_weights = self.dropout(attn_weights)
context_vec = (attn_weights @ values).transpose(1,2)
context_vec = context_vec.contiguous().view(b, num_tokens, self.d_out)
context_vec = self.out_proj(context_vec)
return context_vectorch.manual_seed(123)
batch_size, context_length, d_in = batch.shape
d_out = 2
mha = MultiHeadAttention(d_in, d_out, context_length, 0.0, num_heads=2)
context_vecs = mha(batch)
print(context_vecs)
print("context_vecs.shape:", context_vecs.shape)tensor([[[0.3190, 0.4858],
[0.2943, 0.3897],
[0.2856, 0.3593],
[0.2693, 0.3873],
[0.2639, 0.3928],
[0.2575, 0.4028]],
[[0.3190, 0.4858],
[0.2943, 0.3897],
[0.2856, 0.3593],
[0.2693, 0.3873],
[0.2639, 0.3928],
[0.2575, 0.4028]]], grad_fn=<ViewBackward0>)
context_vecs.shape: torch.Size([2, 6, 2])