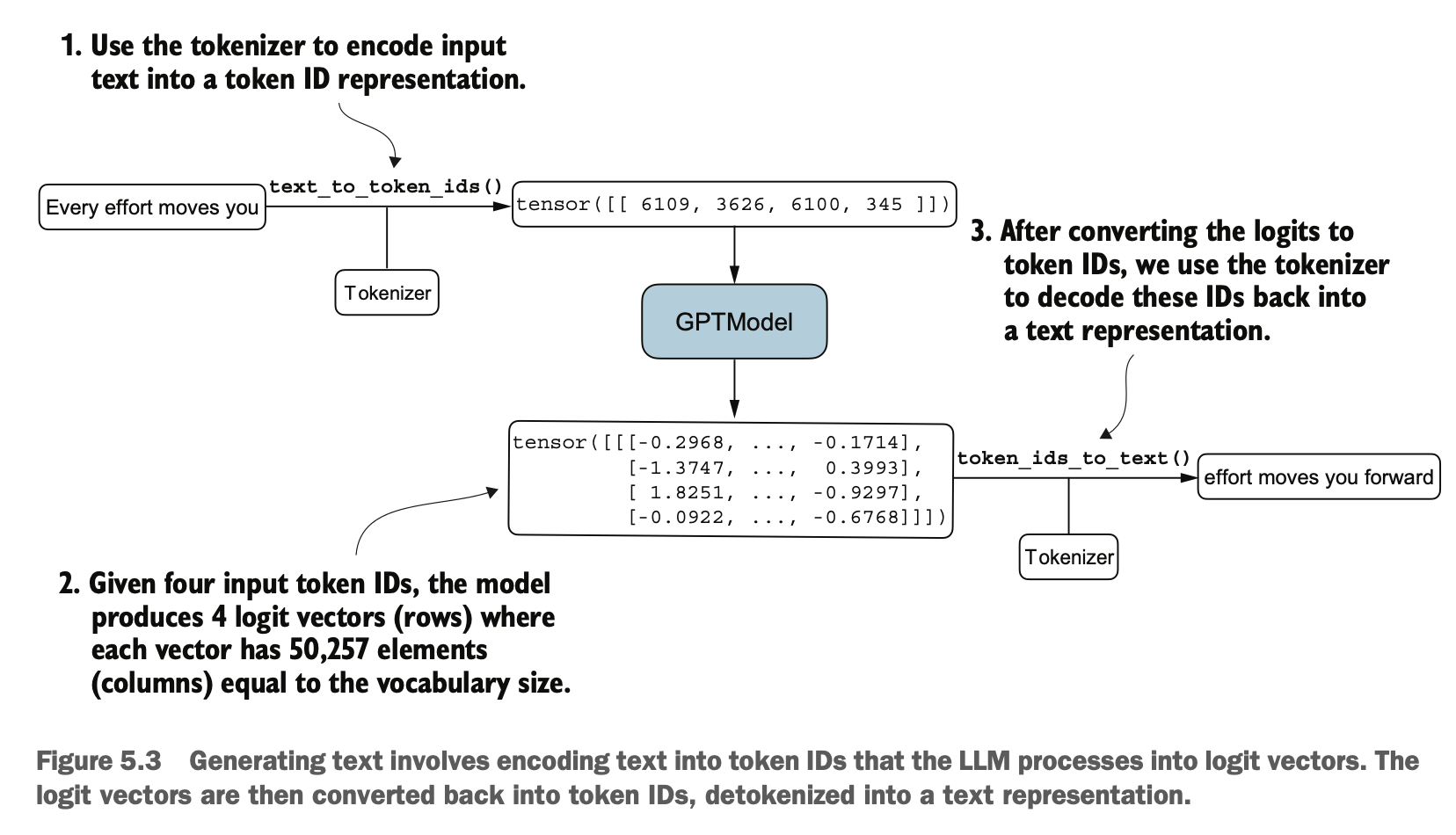
GPTModel(
(tok_emb): Embedding(50257, 768)
(pos_emb): Embedding(256, 768)
(drop_emb): Dropout(p=0.1, inplace=False)
(trf_blocks): Sequential(
(0): TransformerBlock(
(att): MultiHeadAttention(
(W_query): Linear(in_features=768, out_features=768, bias=False)
(W_key): Linear(in_features=768, out_features=768, bias=False)
(W_value): Linear(in_features=768, out_features=768, bias=False)
(out_proj): Linear(in_features=768, out_features=768, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(ff): FeedForward(
(layers): Sequential(
(0): Linear(in_features=768, out_features=3072, bias=True)
(1): GELU()
(2): Linear(in_features=3072, out_features=768, bias=True)
)
)
(norm1): LayerNorm()
(norm2): LayerNorm()
(drop_shortcut): Dropout(p=0.1, inplace=False)
)
(1): TransformerBlock(
(att): MultiHeadAttention(
(W_query): Linear(in_features=768, out_features=768, bias=False)
(W_key): Linear(in_features=768, out_features=768, bias=False)
(W_value): Linear(in_features=768, out_features=768, bias=False)
(out_proj): Linear(in_features=768, out_features=768, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(ff): FeedForward(
(layers): Sequential(
(0): Linear(in_features=768, out_features=3072, bias=True)
(1): GELU()
(2): Linear(in_features=3072, out_features=768, bias=True)
)
)
(norm1): LayerNorm()
(norm2): LayerNorm()
(drop_shortcut): Dropout(p=0.1, inplace=False)
)
(2): TransformerBlock(
(att): MultiHeadAttention(
(W_query): Linear(in_features=768, out_features=768, bias=False)
(W_key): Linear(in_features=768, out_features=768, bias=False)
(W_value): Linear(in_features=768, out_features=768, bias=False)
(out_proj): Linear(in_features=768, out_features=768, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(ff): FeedForward(
(layers): Sequential(
(0): Linear(in_features=768, out_features=3072, bias=True)
(1): GELU()
(2): Linear(in_features=3072, out_features=768, bias=True)
)
)
(norm1): LayerNorm()
(norm2): LayerNorm()
(drop_shortcut): Dropout(p=0.1, inplace=False)
)
(3): TransformerBlock(
(att): MultiHeadAttention(
(W_query): Linear(in_features=768, out_features=768, bias=False)
(W_key): Linear(in_features=768, out_features=768, bias=False)
(W_value): Linear(in_features=768, out_features=768, bias=False)
(out_proj): Linear(in_features=768, out_features=768, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(ff): FeedForward(
(layers): Sequential(
(0): Linear(in_features=768, out_features=3072, bias=True)
(1): GELU()
(2): Linear(in_features=3072, out_features=768, bias=True)
)
)
(norm1): LayerNorm()
(norm2): LayerNorm()
(drop_shortcut): Dropout(p=0.1, inplace=False)
)
(4): TransformerBlock(
(att): MultiHeadAttention(
(W_query): Linear(in_features=768, out_features=768, bias=False)
(W_key): Linear(in_features=768, out_features=768, bias=False)
(W_value): Linear(in_features=768, out_features=768, bias=False)
(out_proj): Linear(in_features=768, out_features=768, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(ff): FeedForward(
(layers): Sequential(
(0): Linear(in_features=768, out_features=3072, bias=True)
(1): GELU()
(2): Linear(in_features=3072, out_features=768, bias=True)
)
)
(norm1): LayerNorm()
(norm2): LayerNorm()
(drop_shortcut): Dropout(p=0.1, inplace=False)
)
(5): TransformerBlock(
(att): MultiHeadAttention(
(W_query): Linear(in_features=768, out_features=768, bias=False)
(W_key): Linear(in_features=768, out_features=768, bias=False)
(W_value): Linear(in_features=768, out_features=768, bias=False)
(out_proj): Linear(in_features=768, out_features=768, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(ff): FeedForward(
(layers): Sequential(
(0): Linear(in_features=768, out_features=3072, bias=True)
(1): GELU()
(2): Linear(in_features=3072, out_features=768, bias=True)
)
)
(norm1): LayerNorm()
(norm2): LayerNorm()
(drop_shortcut): Dropout(p=0.1, inplace=False)
)
(6): TransformerBlock(
(att): MultiHeadAttention(
(W_query): Linear(in_features=768, out_features=768, bias=False)
(W_key): Linear(in_features=768, out_features=768, bias=False)
(W_value): Linear(in_features=768, out_features=768, bias=False)
(out_proj): Linear(in_features=768, out_features=768, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(ff): FeedForward(
(layers): Sequential(
(0): Linear(in_features=768, out_features=3072, bias=True)
(1): GELU()
(2): Linear(in_features=3072, out_features=768, bias=True)
)
)
(norm1): LayerNorm()
(norm2): LayerNorm()
(drop_shortcut): Dropout(p=0.1, inplace=False)
)
(7): TransformerBlock(
(att): MultiHeadAttention(
(W_query): Linear(in_features=768, out_features=768, bias=False)
(W_key): Linear(in_features=768, out_features=768, bias=False)
(W_value): Linear(in_features=768, out_features=768, bias=False)
(out_proj): Linear(in_features=768, out_features=768, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(ff): FeedForward(
(layers): Sequential(
(0): Linear(in_features=768, out_features=3072, bias=True)
(1): GELU()
(2): Linear(in_features=3072, out_features=768, bias=True)
)
)
(norm1): LayerNorm()
(norm2): LayerNorm()
(drop_shortcut): Dropout(p=0.1, inplace=False)
)
(8): TransformerBlock(
(att): MultiHeadAttention(
(W_query): Linear(in_features=768, out_features=768, bias=False)
(W_key): Linear(in_features=768, out_features=768, bias=False)
(W_value): Linear(in_features=768, out_features=768, bias=False)
(out_proj): Linear(in_features=768, out_features=768, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(ff): FeedForward(
(layers): Sequential(
(0): Linear(in_features=768, out_features=3072, bias=True)
(1): GELU()
(2): Linear(in_features=3072, out_features=768, bias=True)
)
)
(norm1): LayerNorm()
(norm2): LayerNorm()
(drop_shortcut): Dropout(p=0.1, inplace=False)
)
(9): TransformerBlock(
(att): MultiHeadAttention(
(W_query): Linear(in_features=768, out_features=768, bias=False)
(W_key): Linear(in_features=768, out_features=768, bias=False)
(W_value): Linear(in_features=768, out_features=768, bias=False)
(out_proj): Linear(in_features=768, out_features=768, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(ff): FeedForward(
(layers): Sequential(
(0): Linear(in_features=768, out_features=3072, bias=True)
(1): GELU()
(2): Linear(in_features=3072, out_features=768, bias=True)
)
)
(norm1): LayerNorm()
(norm2): LayerNorm()
(drop_shortcut): Dropout(p=0.1, inplace=False)
)
(10): TransformerBlock(
(att): MultiHeadAttention(
(W_query): Linear(in_features=768, out_features=768, bias=False)
(W_key): Linear(in_features=768, out_features=768, bias=False)
(W_value): Linear(in_features=768, out_features=768, bias=False)
(out_proj): Linear(in_features=768, out_features=768, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(ff): FeedForward(
(layers): Sequential(
(0): Linear(in_features=768, out_features=3072, bias=True)
(1): GELU()
(2): Linear(in_features=3072, out_features=768, bias=True)
)
)
(norm1): LayerNorm()
(norm2): LayerNorm()
(drop_shortcut): Dropout(p=0.1, inplace=False)
)
(11): TransformerBlock(
(att): MultiHeadAttention(
(W_query): Linear(in_features=768, out_features=768, bias=False)
(W_key): Linear(in_features=768, out_features=768, bias=False)
(W_value): Linear(in_features=768, out_features=768, bias=False)
(out_proj): Linear(in_features=768, out_features=768, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(ff): FeedForward(
(layers): Sequential(
(0): Linear(in_features=768, out_features=3072, bias=True)
(1): GELU()
(2): Linear(in_features=3072, out_features=768, bias=True)
)
)
(norm1): LayerNorm()
(norm2): LayerNorm()
(drop_shortcut): Dropout(p=0.1, inplace=False)
)
)
(final_norm): LayerNorm()
(out_head): Linear(in_features=768, out_features=50257, bias=False)
)